New Year’s Eve Question December 31, 2007
Posted by Alexandre Borovik in Uncategorized.1 comment so far
Edge still has not revealed its New Year’s Eve Annual Question 2008, but, due to a leak to The Independent, I know that it is i wonderful:
What have you changed your mind about? Why?
Indeed, what have you changed your mind about in 2007?
Other blogs December 27, 2007
Posted by dcorfield in Uncategorized.add a comment
Something we won’t be ignoring is relevant discussion on other blogs, and here’s some of that going on at Richard Borcherds’ blog. They’re wondering why so little of the power of set theory gets used in the vast majority of mathematics.
Case Study V: Ubiquity of finite fields December 21, 2007
Posted by Alexandre Borovik in Uncategorized.4 comments
Zadaje pytania wymijajace, by przeciac droge wymijajacym odpowiedziom.I ask circumspect questions to avoid circumspect answers.
Whenever you discuss the realities of mathematical life, words of wisdom from Vladimir Arnold, an outspoken critic of the status quo of modern mathematics, often help to clarify the issues:
All mathematics is divided in three parts: cryptography (paid for by the CIA, the KGB and the like), hydrodynamics (supported by manufacturers of atomic submarines) and celestial mechanics (financed by the military and by other institutions dealing with missiles, such as NASA).
Cryptography has generated number theory, algebraic geometry over finite fields, algebra, combinatorics and computers.
Let us pause here and, ignoring the irony of Arnold’s words, take them at face value. Indeed, why there is so much fuss around finite fields? Why is modern, computer-implemented cryptography based on finite fields?
This question is relevant to our discussion since computers can be viewed as very crude models of a mathematical brain. One of the major problems of human mathematics — and the battleground of platonists and formalists — is why mathematics chooses to operate within a surprisingly limited range of basic structures. Why does it reuse, again and again, the same objects? It is this aspect of mathematical practice that turns many mathematicians into instinctive (although not very committed) platonists.
But why not ask the same question about computers? Let us make it more specific: why is the range of structures usable in computer-based cryptography so narrow? Unlike the philosophical questions of mathematics, this last question has the extra bonus of having very obvious practical implications.
Imagine that the proverbial little green men from Mars stole a satellite from its orbit around Earth and attempted to analyze the dedicated microchip responsible, say, for the Diffie-Hellman key exchange. Would they be surprised to discover that humans were using finite fields and elliptic curves?
For further discussion, we need some details of the Diffie-Hellman key exchange. I repeat its basic setup in a slightly more abstract way than is usually done.
Alice and Bob want to make a shared secret key for the encryption of their communications. Until they have done so, they can use only an open line communication, with Clare eavesdropping on their every word. How could they exchange the key in open communication so that Clare would not also get it?
The famous Diffie-Hellman key exchange protocol is a procedure which resolves this problem. Historically, it is one of the starting points of modern cryptography. In an abstract setting, it looks like this:
- Alice and Bob choose a big finite abelian group
(for our convenience, we assume that the operation in
. (As the result of her eavesdropping, Clare also knows
.)
- Alice selects her secret integer
, computes
and sends the value to Bob. (Clare knows
- Similarly, Bob selects his secret integer
and sends to Alice
. (Needless to say, Clare duly intercepts
- In the privacy of her computer (a major and delicate assumption) Alice raises the element
. (Clare does not know the result unless she has managed to determine Alice’s secret exponent
- Similarly, Bob computes
.
- Since
, the element
is the secret shared element known only to Alice and Bob, but not to Clare. The string of symbols representing
So, what do we need for the realization of this protocol? I will outline the technical specifications only in a very crude form; they can be refined in many ways, but there is no need to do that here, a crude model will suffice.
Since we can always replace 
Therefore, to implement the Diffie-Hellman key exchange, we need:
- A cyclic group
) strings of 0s and 1s.
- The group operation has to be quick, in any case, better than in
basic operations of the computer.
- The discrete logarithm problem of finding the secret exponent
in
- This should preferably (but not necessarily) be done for an arbitrary prime
- The implementation of the particular instances of the algorithm, compilation of the actual executable file for the computer (or realization of the algorithm at the hardware level in a microchip, say, in a mobile phone) should be easy and done in polynomial time of small degree in
.
There are two classical ways of making cyclic groups 

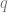




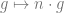
How can we compare different computational structures for

and

Elements of 



given by 
An impressive body of mathematics has been developed over the last half century for efficient implementation of exponentiation, with the likes of Paul Erdos and Donald Knuth involved.
We shall say that the implementation of
As Blake, Seroussi and Smart comment in the introduction to their book on elliptic curve cryptography, the three types of groups we just mentioned represent the three principal classes of commutative algebraic groups over finite fields: unipotent —
curves. They can all be built from finite fields, by simple constructions with fast computer implementations. So far I am aware of only one another class of computational structures for finite abelian groups proposed for use in cryptography, “ideal class groups” in number fields (but it is not clear to me whether they allow a cheap mass set-up).
My million dollar question is
Are there polynomial time computational structures for cyclic groups of prime order (which therefore have a chance to meet memory and speed requirements of computer-based cryptography) and which cannot be reduced, within polynomial space/time constraints, to one of the known types?
Notice that non-reducibility to
I accept that this question is likely to be out of reach of modern mathematics. The answer will definitely involve some serious advances in complexity theory. If the answer is “yes”, especially if you can invent something which is quicker than elliptic curve systems, you can patent yourinvention and make your million dollars. If the answer is “no” — and this is what I expect — it will provide some hint as to how similar questions can be asked about mathematical algorithms and structures acceptable for the human brain and about algorithms implemented in the brain at the innate, phylogenic level.
Meanwhile, mathematics already has a number of deep results which show the very special role of finite fields in the universe of all finite structures; we shall discuss one such theorem later.
[Cannibalised from my book; you can find references, etc. there.]
Manifestation of Infinity December 18, 2007
Posted by Alexandre Borovik in Uncategorized.4 comments
According to Vladimir Arnold (see my previous post), these are manifestations of infinity in the real world:


Commented out December 17, 2007
Posted by Alexandre Borovik in Uncategorized.12 comments
I want to add that I plan to touch in our blog a theme which was commented out from our grant proposal as excessively controversial:
% \subsection*{And the last, but not least\dots}
%
% We shall try to sort out the mess of misunderstanding surrounding
% the concept of infinity in literature on mathematical education.
A language question: is the expression “to comment out” used outside of TeX and programming communities?
The issue of infinity in education is interesting in view of Peter McBurney’s commented on my post “Case Study III: Computer science: The bestiary of potential infinities”:
Your example from Computer Science reminds me of something often forgotten or overlooked in present-day discussions of infinite structures: that some of the motivation for the study of the infinite in mathematics in the 19th and early 20th centuries came from physics where (strange as it may seem to a modern mathematician or a computer scientist) the infinite was used as an approximation to the very-large-finite.
I had personal learning experience related to that issue. It so happened that I was a guinea pig in a bold educational experiment: at my boarding school, my lecturer in mathematics attempted to build the entire calculus in terms of finite elements. It sounded like a good idea at the time: physicists formulate their equations in terms of finite differences — working with finite elements of volume, mass, etc, then they take the limit

and replace 




And I learned to love actual infinity — it makes life so much easier.
My story, however, has a deeper methodological aspect. Vladimir Arnold forcefully stated in one of his books that it is wrong to think about finite difference equations as approximations of differential equations. It is the differential equation which approximates finite difference laws of physics; it is the result of taking an asymptotic limit at zero. Being an approximation, it is easier to solve and study.
In support to his thesis, Arnold refers to a scene almost everyone has seen: old tires hanging on sea piers to protect boats from bumps. If you control a boat by measuring its speed and distance from the pier and select the acceleration of the boat as a continuous function of the speed and distance, you can come to the complete stop precisely at the wall of the pier, but only after infinite time: this is an immediate consequence of the uniqueness theorem for solutions of differential equations. To complete the task in sensible time, you have to alow your boat to gently bump into the pier. The asymptotic at zero is not always an ideal solution in the real world. But it is easier to analyze!
[Here, I cannibalise a fragment from my book.]
Centre for Reasoning December 16, 2007
Posted by dcorfield in Uncategorized.add a comment
Anyone interested in doing postgraduate work with me in philosophy of mathematics, relating perhaps to the subject matter of this blog or my other one, is very welcome. If you came to Kent you could be part of the Centre for Reasoning, directed by myself and Times Higher Education Supplement Young Researcher of the year, Jon Williamson. We will be running an MA from September 2008.
Case Study IV: omega-categories December 15, 2007
Posted by Alexandre Borovik in Uncategorized.5 comments
In higher-dimensional algebra, also known as higher-dimensional category theory, you encounter a ladder which you are irresistibly drawn to ascend. Let us begin with a finite set. About two elements of this set you can only say that they are the same or that they are different. Thinking about sets a little harder, you are led to consider what connects them, namely, functions (or perhaps relations). Taken together, sets and functions form a category. Now, there are two levels of entity, the objects (sets) and the arrows (functions), satisfying some conditions, existence of identity arrows and associative composition of compatible arrows.
There are plenty of examples of categories. For example, categories of structured sets, such as groups and homomorphisms, but also spatial ones, such as 2-Cob, whose objects are sets of circles and whose arrows are (diffeomorphism) classes of surfaces between them. A pair of pants/trousers represents an arrow from a single circle (the waist) to a pair of circles (the trouser cuffs) in this latter category.
In a category, the arrows between two objects 

Let us continue up the ladder. Consider categories long enough, and you will start to think of functors between categories, and natural transformations between functors. Functors are ways of mapping one category to another. If the first category is a small diagram of arrows, a copy of that diagram within the second category would be a functor. Natural transformations are ways of mediating between two images within the target category. Taking all (small) categories, functors, and natural transformations, we have an entity with three levels, which we draw with dots, arrows and double-arrows. This is an example of a 2-category, the next rung of the ladder. In this setting, whether objects are the `same’ is not treated most generally as isomorphism, but as equivalence. Between equivalent objects there is a pair of arrows which do not necessarily compose to give identity arrows, but do give arrows for which there are invertible 2-arrows to these identity arrows.
This is something structuralists have missed. At the level of categories, isomorphism is too strong a notion of sameness. Anything you can do with, say, the category of finite sets, you can do with the equivalent (full) sub-category composed of a representative object for each finite number and functions between them.
Then, one more step up the ladder, 2-categories form a 3-category, with four levels of entity. Another example of a 3-category is the fundamental 3-groupoid of a space. Take the surface of a sphere, such as the world. Objects are points on the globe. 1-arrows between a pair of objects, say the North and South Poles, are paths. 2-arrows between pairs of 1-arrows, say the Greenwich Meridian and the International Date Line, are ways of sweeping from one path to the other. Finally, a 3-arrow between a pair of 2-arrows, say one that proceeds at a uniform rate between the Greenwich Meridian and the International Date Line and the other that tarries a while over New Delhi, is represented by a way of interpolating between these sweepings.
Mathematicians are aiming to extend this process infinitely far to infinite-dimensional categories, so-called 
There is a deep question here of why a complete treatment of sameness requires the construction of infinitely layered entities.
Case Study III: Computer Science: The bestiary of potential infinities December 15, 2007
Posted by Alexandre Borovik in Uncategorized.8 comments
We quote a professional computer scientist who left the following comment on the blog of one of us:
I would caution everyone … not to confuse “mathematical thinking” with “The thinking done by computer scientists and programmers”.
Unfortunately, most people who are not computer scientists believe these two modes of thinking to be the same.
The purposes, nature, frequency and levels of abstraction commonly used in programming are very different from those in mathematics.
We would like to illustrate the validity of these words on a very simple example.
Let us look at a simple calculation with MATLAB, an industry standard software package for mathematical computations.
>> t= 2
t = 2
>> 1/t
ans = 0.5000
What is shown in this screen dump is a basic calculation which uses floating point arithmetic for computations with rounding.
Next, let us make the same calculation with a different kind of integers:
>> s=sym(‘2’)
s = 2
>> 1/s
ans = 1/2
Here we use “symbolic integers”, designed for use as coefficients in symbolic expressions.
Next, let us try to combine the two kinds of integers in a single calculation:
>> 1/(s+t)
ans = 1/4
We observe that the sum 

Examples involving analytic functions are even more striking:
>> sqrt(t)
ans = 1.4142
>> sqrt(s)
ans = 2^(1/2)
>> sqrt(t)*sqrt(s)
ans = 2
We see that MATLAB can handle two absolutely different representations of integers, remembering, however, the intimate relation between them.
The example above is written in C++}. When represented in C++, even the simplest mathematical objects and structures appear in the form of (a potentially infinite variety of) classes linked by mechanisms of inheritance and polymorphism. This is a manifestation of one of the paradigms of the computer science: if mathematicians instinctively seek to build their discipline around a small number of “canonical” (actually) infinite structures, computer scientists frequently prefer to work with a host of potential infinities controlled and handled with the help of a special technique which is category-theoretic by its nature. In the context of Computer Science, a category-theoretic approach frequently has an advantage over the set-theoretic: in the example above, the set of “symbolic” integers appears as a process for building its elements; it is not closed, its boundaries are not defined. We find ourselves in the situation summarised in the famous words by Henri Poincare:
“There is no actual infinity; and when we speak of an infinite collection, we understand a collection to which we can add new elements unceasingly.”
When we move from integers to other algebraic structures ofinterest for practical applications, for example, (finite)abelian groups and finite fields, we see a real explosion in variety and diversity of their computer realisations. Ofcourse, any two Galois fields of the same order 
The link between computer science and category theory is especially interesting because we shall look, in the next case study, at the real time emergence of yet another form of actual infinity in a developing mathematics discipline: the higher-dimensional category theory.
Case Study II: Explication of (in)explicitness December 15, 2007
Posted by Alexandre Borovik in Uncategorized.add a comment
Our second case study will demonstrate an extreme case among many possible approaches to the explication of informal mathematical concepts: a hard-core mathematical treatment of the very concept of “explicitness”. It can be formulated as a remarkably compact thesis:
Explicit = Borel.
This thesis is promoted — perhaps in less explicit form — by Alexander Kechris and Greg Hjorth. A wonderful illustration and a template for the use of the thesis can be found in a recent work by Simon Thomas.
Simon Thomas looked at the following problem:
Does there exist an explicit choice of generators for each finitely generated group such that isomorphic groups are assigned isomorphic Cayley graphs?
Recall that if 

For example, when 

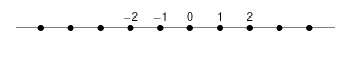
However, when 
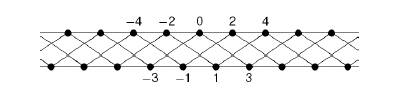
Simon Thomas’ problem is very natural: is there an explicitly given canonical Cayley graph for each finitely generated group? The problem concerns the relation between two basic concepts of algebra: that of a group and its Cayley graph; it is formulated in very elementary terms.
Simon Thomas gave a negative answer to the problem. More precisely, he proved that this assignment cannot be made by a map with a Borel graph.
The underlying concepts of his proof are not that difficult; we give here only a crude description, all details can be found in Thomas’ paper.
First we note that a structure of a group on the set 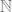



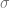
At this point one needs to recall Kuratowski’s Theorem:
Any standard Borel space is isomorphic to one of
(1)
, (2)
In particular, the set 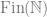
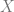
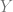


Now I can state Simon Thomas’ Theorem:
There does not exist a Borel map
such that for each group
:
generates
- If
then the Cayley graph of
.
Is the Explicit = Borel thesis reasonable?
Indeed, a Borel subset of 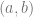
Notice also that it is Kuratowski’s Theorem that brings the feeling of precision and universality into the Explicit = Borel thesis; without it, the thesis would be much more vague.
The Explicit = Borel thesis for the real domain is an example of an “under the microscope” approach to mathematics; it is like cytology, which treats living tissue as an ensemble of cells. Representing everything by 0’s and 1’s gives a very low level look at mathematics; it is fascinating that this approach leads to explicit “global” results.
Case Study I: Zilber’s Field December 15, 2007
Posted by Alexandre Borovik in Uncategorized.3 comments
Many mathematical objects are exceptionally rigid, we cannot change them at will, they offer resistance. The “robustness” of a mathematical object (one may also talk about a dual concept: “robustness” of a mathematical theory which describes the object) has been explicated as a formal mathematical notion, categoricity, in the mathematical discipline called model theory (more precisely, in model-theoretic stability theory). One of the recent results in that theory, Boris Zilber’s work on the Schanuel Conjecture, can be described (but perhaps not formulated in full detail) at a level of elementary algebra/calculus/number theory. It poses a significant philosophical challenge which, to the best of our knowledge, so far has been entirely ignored by the philosophers of mathematics.
The Schanuel Conjecture is about transcendental numbers. It says that if you have 

then the latter has transcendence degree at least 

has transcendence degree at least one, which means that 
Zilber took a number of natural (and known) algebraic properties of complex numbers and the exponentiation function 

added to them, as a further axiom, the formulation of the Schanuel Conjecture (still unknown) and proved:
[1.] The axioms are consistent, that is, they have a model, an algebraically closed field
of characteristic 0 with a formal exponentiation function
of complex numbers with he standard exponentiation).
[2.] There is exactly one, up to isomorphism, such field
And now we can formulate some questions:
- Why would almost every mathematician (with the possible exception of intuitionists and ultrafinitists like Alexander Yessenin-Volpin — but they have an honourable excuse) immediately agree that of course it should be true that
and that therefore the Schanuel Conjecture should be true? What is the basis of this belief in “it should be true”?
- Why does Zilber’s theorem have a suspiciously foundational, metamathematical feel about it?
- Zilber’s field
, despite the two objects having completely different origins?
The appearance of the Fraisse amalgam method on the scene should remind us that even in the countable domain we have a wonderful and paradoxical example of seemingly incompatible constructions leading to the same “universal” object. The famous random graph can be constructed probabilistically by coin tossing: vertices of the graph are natural numbers, and for every pair of vertices 

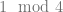
Is the acceptance of actual infinity just the price that mathematicians are prepared to pay for the convenience (and beauty) of the “canonical” objects of mathematics?
